Now that it is ‘Working’ What are we doing?
So everything is looking good. I can drive the simulated bot around a little bit.
Yaw commands are being ignored so lets take a look at that next
Once we get training to a happy place we gotta go back into tackling the hardware problems
Driving the quadruped with command headings (teal line) body_velocity (red line)
Whats wrong with Yaw?
Control of the heading in the x and y local directions seems to work well
Control of yaw is non-existent right now
Early on I was having trouble with the policies learned when there was a variable X and Y command velocity. The simplification to a target heading was done because I thought the mechanical design I made might be very limited in the type of gaits it could generate and I wanted to give it the best chance at finding a successful locomotion policy
Yaw has remained a target condition although I tried simplifying it to be in the set [-1,0,1] exclusively
The reward structure is based on the error between the command signal and the measure signal. It is governed by the equation :
$$e^{-x/e_{scale}}*reward_{scale}$$



You can see as the expScale parameter is increased how we become more rewarding for larger error. We can tune our tolerance to error this way.
Currently, the yaw expScale is set to : 0.05 which reduces our reward to 1.8% at 0.2 units of error
I don’t know if this is too aggressive. It certainly depends on some real world units and the capabilities of this bot.
It is definitely too aggressive for the discrete set of yaw speeds [-1, 0, 1] but might be better for the uniform distribution from (-1, 1)
I think that since there is always a positive gradient with error minimization, going for larger expScale is still advisable
At expScale = 0.25, we reduce the reward by 45% at 0.2 units of error and by 1.8% at 1.0 units of error.
I am a little sceptical large expScales as we reward bad behavior (yawing in the wrong direction) and might not correct it? I’m not 100% sure on this though since as stated above, there is still a positive reward gradient to the target setpoint.
So the current training still has no yaw response, this is the reward trajectory so far. I might try continuing from this training with the modified rewards and see what happens.

I am allowing yaw to be selected from the uniform distribution in (-1, 1)
I am setting the expScale at 0.25 for now.
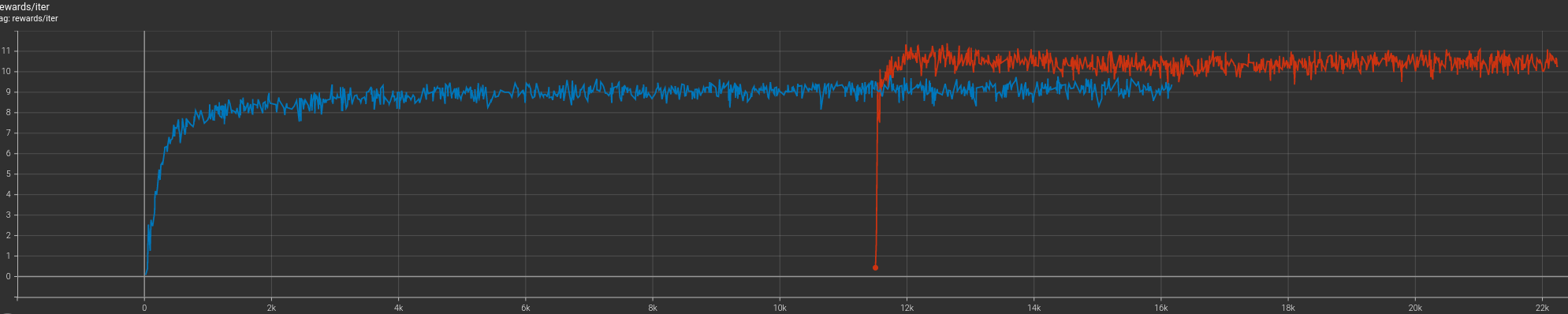
After training for a bit, there still is no response to the yaw command. The reward is higher because we’ve changed the expScale which allows for more reward to be collected from higher yaw rate errors. Lets try one more from scratch and see if maybe it picks up on the yaw commands this time.
Aaannnnnndddd It all seems to work!!!!!
Nice!
Can we go back to target velocities instead of target headings?
Idk why not… Yaw seems to work ok…
Lets get an idea for what our current achievable speeds are so we can make the velocity range realistic.
It seems to be just peaking over 0.1 m/s
I’m going to set the range to +/- 0.125 m/s
I dropped yaw from 1.0 rad/sec to 0.5 rad/sec.
It was pretty good at doing yaws, they were a little fast
It really seems to struggle with target velocities instead of target heading. It might be worth coming back to tackle this in the future but things are working well enough as is for deployment. I need to move onto getting the hardware together for now and I’ll come back to this one in the future
Getting Unstuck : Learning Failure after Reduced State Observations
I’ve switched to a quadruped design to start, I think the added stability of two more legs will give me a better chance at early success in my sim to real work. It allows for a larger chassis size which I needed for additional components like a battery, power distribution system, and a real-sense camera. All in all I think this a good direction for now and I’ll return to the two legged variant when I have a better understanding of the sim to real challenges I will be facing.
So lets recap. Basically for months, I’ve been stuck with a bug of sorts. The learned policies when given the “Gods Eye” observations (Full State knowledge) were really good. There robots were able to locomote well. The reduced observation set has consistently had issues with learning good policies.
Originally I was creating a simulated IMU type measurement and feeding the raw signals to the network
Now I’m just calculating the local velocity and angular velocity and giving that to the network
I imagined orientation could be learned from the IMU signals but processing it and feeding the results in will probably save some training time
This hasn’t been done yet
I wasn’t sure what type of bug I was looking for. Tensor shapes have been such a common source of problems that I tend to always start here. I also had changed the reward and observation at the same time, so I wasn’t sure if the bug was in one or the other. To me, how the reward is given could have been a source of problems. The early reward structure was attempting to match the robots local vel with the command vel. I imagine if the robot was only able to walk well at one specific speed (Due to my slapdash design), this type of reward could be very detrimental to the learning process. I switched over to matching a command heading with any achievable velocity, although this could have it’s pitfalls as well. Coupled with rewards designed to minimize torque, it may learn how to move but at a very low speed.
I want to have a hybrid of the first reward structure and the current command input style I was going for. We basically can set the target location to :
Walkbot_Pos * Command_Vel * dt
Anyways there have been training problems and I’ve been picking apart the code for bugs for a while now. I think I finally stumbled into some positive news, providing roll-pitch-yaw data seems to have helped train working polices.