Learning to Walk
This is a continuation of the CubeBot control documentation that can be found here :
In this section I will make modifications to the CubeBot code to reward it to move to goal locations. The major modifications I make are :
Reducing the action space from 6 to 3. In the previous examples, the 6 wheels were all receiving independent commands. Now parallel wheels will receive the same command.
Switching from Velocity Control to Torque Control. The actions will be command torques to the motors
This required setting up a simple motor model that limits available torque as a function of DOF rotational velocity
Added a second actor to each environment that represents a goal position. This actor is a green ball.
CubeBots can only reach the goal that exists in their personal environment
Without filtering collisions, CubeBots CAN push other environments goal spheres around :)
Modification to the Observation Tensor
Additional Observations include goal position and direction
Velocities observations were switched from the global coordinate frame to the local robot coordinate frame
The observation function is redefined as a jit script
Modification to the Reward Tensor
The reward is composed of a “progress” reward and a “goal reached” reward
Increased the number of environments. Since environments are in parallel, we have higher samples rate relative to clock time.
80M steps are generated in 7 minutes as oppose to 22 minutes in the previous example!
In an hour
Modifying the test code
Adding a goal object
Modifying the Observation
Modifying the Reward
Moving to Torque Control
One of the things I wanted to do was switch away from the velocity controller that is built into Isaac and directly use torque control. One thing I noticed was that while the DOF velocity would still be limited to the value set in the dof_properties, you could continue to apply torque at the joint which would act on the base. To fix this problem I needed to make a simple motor model that would limit the available torque as a function of the current DOF velocity.
To start lets look at what the velocity controller in Isaac Gym is actually doing :
Torque = (PosError)(Stiffness) + (VelError)(Damping)

Damping = 2, Stiffness = 0.0

Damping = 0.0, Stiffness = 2

Damping = 2, Stiffness = 2
Above we can see the individual contributions to the torque signal from Vel Error, Pos Error, and both combine. In the plots blue indicates negative torque, red indicates positive torque and white is zero torque. The signal saturates when the torque is equal to 1 which is why we see the plateau areas for large error values. Additionally, The position Error and Velocity Errors are orthogonal and when combine give us an idea of the torque we can expect for a given combination of errors. There is an interesting line where position error and velocity error have opposite signs and produce 0 torque even for large errors.
The way motors work is that a voltage is generated through the motion of the rotor known as back emf. As the velocity increase, the back emf increase and reduces the ability for the system to push more current through the system. This is due to a limited drive voltage available. I wanted to simulate this in a simple manor without producing a full motor model right now. wE will have to calculate this for the upper and lower bound. If the motor is spinning in the positive direction, positive torque will be limited but the system should still be able to achieve full negative torque.
k = maxTorque/maxSpeed max_available_torque = maxTorque - dof_vel*k min_available_torque = -maxTorque - dof_vel*k Torque = np.clip(TorqueTarget, min_available_torque, max_available_torque)

Looking at the plot above, we can see for a given input (DOF Vel, Target Torque) we produce an (Actual Torque) on the Z-axis. The actual torque shows the clipping of the target torque by the bends in the surface. We can see that when the DOF Vel is positive, the Torque Target is clipped proportional to the DOF speed until it hits 0 at max speed. This scaling is achieved by setting k = maxTorque/maxSpeed. If the DOF Vel is negative, a positive Target Torque is not clipped. The same can be seen for negative DOF Vels and negative torques. At full velocity (-1 or 1) we are no longer able to generate torque to increase the DOF velocity. One last modification I think is worth making is to include a parameter to scale the clipping slope. This is to allow us to achieve full torque in the direction we are moving at least for a portion of lower DOF velocities. We want to change the clip slope while still keeping the torque at maxSpeed 0. I produced the functions below by playing with the functions for a bit. It kind of looks like a low pass digital filter. Offset functionally changes the clipping slope, so offset > 1 will increase the steepness while offset<1 will decrease the steepness
offset = 2 k = maxTorque/maxSpeed max_available_torque = maxTorque - (offset*dof_vel*k + (1-offset)*maxTorque) min_available_torque = -maxTorque - (offset*dof_vel*k - (1-offset)*maxTorque)

offset = 0.6
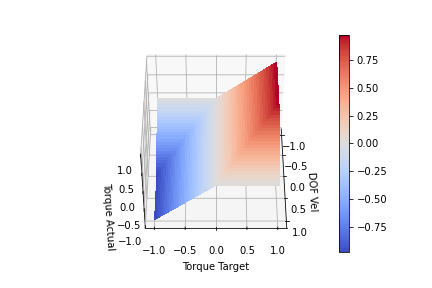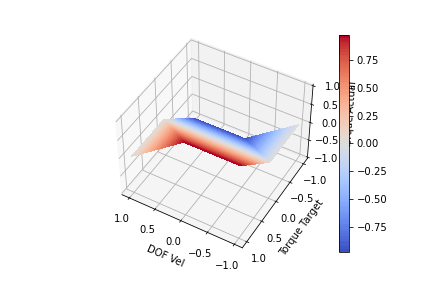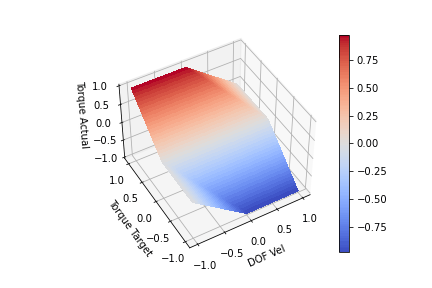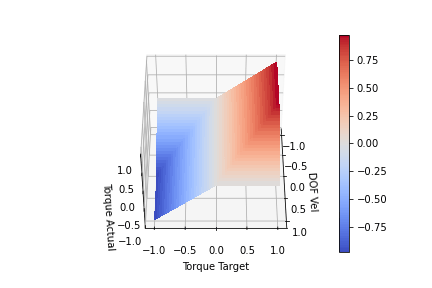
offset = 1.0

offset = 2.0
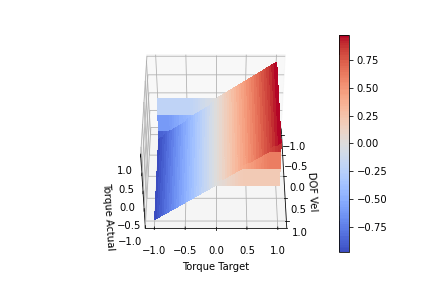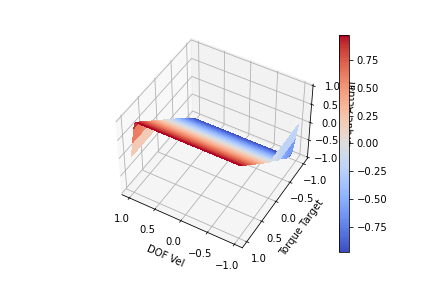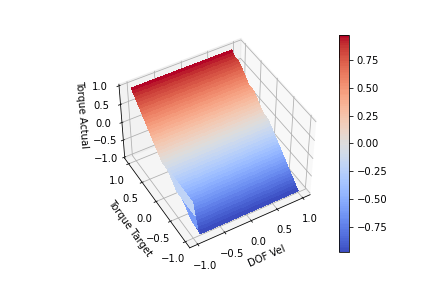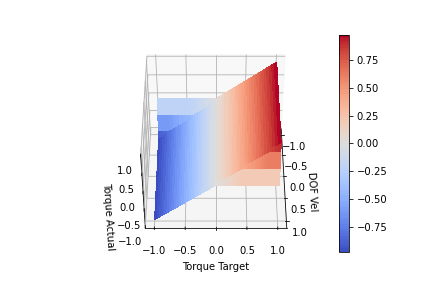
offset = 10.0
note : offsets below 0.5 will start limiting the maximum available torque across all operating points :

offset = 0.25
Extra Notes :
Environments are created in a way that no two agents can physically interact with each other. They are rendered in the same space but will pass through each other. This is something that can be modified when assets are instantiated with the create_actor function by setting the collision_group and collision_filter to the same number
param5 (int) – collision group that actor will be part of. The actor will not collide with anything outside of the same collisionGroup
param6 (int) – bitwise filter for elements in the same collisionGroup to mask off collision
# No Collisions cubebot_handle = self.gym.create_actor(env_ptr, cubebot_asset, pose, "cubebot", i, 1, 0) goal_handle = self.gym.create_actor(env_ptr, goal_asset, goal_pose, "goal", i, 1, 1) # All Collisions cubebot_handle = self.gym.create_actor(env_ptr, cubebot_asset, pose, "cubebot", 0, 0, 0) goal_handle = self.gym.create_actor(env_ptr, goal_asset, goal_pose, "goal", 0, 0, 1)