Introduction
The motivation of this project is to attempt a sim to real control policy. This will be a logical continuation of the work from CubeBot. I’ll be modifying the training code to use the robot design in the previous section : WalkBot Design.
The code for this project can be found at :
Setting up the training code
I will return to this section. I’ve been enjoying playing with the parameters and am prioritizing documenting the trials I am running first.
Experimenting with the code
I’d like to use this section to keep track of the different parameters I’ve tried while trying to get this code to work. There are a few variables to play with
The motor parameters. I want to have an understanding of how the trade off of torque and speed effect the walking policy.
Termination Height : It appears that the termination height seems to guide the learning process by eliminating undesired locomotive paradigms… What does that mean? I end the training episode if the height (z) falls below a certain threshold. I would like the robot to learn to walk on it’s foot link but if allowed, the robot will learn a more stable position closer to the ground. I assume with a long enough training routine and the right reward structure it should learn how to walk ‘correctly’. By setting this termination height correctly you prevent the agent from ever getting to those less desirable states. Below are videos showing the control policy learned with and without the termination height, all other parameters kept constant.
Environment Parameters
Static and Dynamic friction.
The first tests I’ve run had friction coefficients of 1.0 This isn’t realistic for the materials I’ve chosen and a lower value might represent the real world better. I’m curious how this parameter may effect the control policy though.
Reward Shaping for more ‘desirable?’ performance
One of the things I’ve noticed is that the control policy seems to converge quickly on the ankle joints being in opposition. It may just be my desire for symmetry but I want to see a final policy where the feet face the same direction. I am adding a small penalty for the difference in the ankle joint angles to encourage a more biologic looking gait.
Motor Comparison : M077 vs M288
There are two different servo motors available in the same package. The difference between the two is the gear ratio, so there is a trade off between torque and speed
M077
Speed = 38.0 rad/sec
Torque = 0.22 N/m
M288
Speed = 10.9 rad/sec
Torque = 0.52 N/m


After training both policies it seems that the faster motors result in a better final control policy. I might need to see if this is still the case if I increase the mass of the body. This is currently set to 0.1 Kg which sounds like it might be a little to light. I will try a larger value for this for comparison.
M077 Motor Parameters
M288 Motor Parameters
While trying different combinations of parameters, I noticed that the M288 perform slightly better in an environment with a lower friction coefficient. They still do not reach the performance of the M077 Motors. For tests moving forward I’ll be testing with the M077 leg parameters due to the better policy it is able to achieve.


M288 with high surface friction
M288 with low surface friction
Termination Height
The termination height is a value that controls when an episode is considered a failure. The root Z coordinate of the body is compared to the termination height. If the root Z coordinate falls below the termination height, the episode ends and a penalty is applied to the reward. Below are some examples of control policies learned with different termination heights.
Termination Height = 0.16
Termination Height = 0.08
Termination Height = 0.02
I think by preventing the agent from reaching these other states, we promote faster learning. I would hope that over time the policies would converge but it appears to get trapped in these local minimums. I am not sure how long I’d need to train to get a better policy though. I think looking at the rewards over time might be insightful though.

Orange : TermHeight = 0.16.
Blue : TermHeight = 0.08.
Red : TermHeight = 0.02
The rewards are pretty similar despite visually performing rather differently. I think plotting the individual contributions to the overall reward might be useful.

TermHeight = 0.16

TermHeight = 0.08

TermHeight = 0.02
The height reward might not be large enough to drive the learning process to stand. This reward shaping is a little… over specific.
I’m also going to multiply the Height Reward by 4 so it’s maximum value will be 1. (This is unreachable, it just spawns at 0.25 units initially)
Scaling the Height Reward didn’t result in a different policy when compared with the original for the duration of the training. Training might be too short though.
I wonder if it will learn a better policy with more training. I might try and see if the TermHeight = 0.08 transitions into a policy like TermHeight = 0.16 given enough time.
I’ll run this overnight tonight.
Friction Parameters
I ran two trials for this test :
Trial 1 : Static and Dynamic Friction = 1.0
Trial 2 : Static and Dynamic Friction = 0.5
The performance will be compared by comparing the rewards achieved over time :

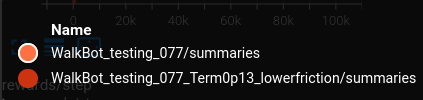
The lower friction environment took a little longer to reach a similar level of performance. Overall the control policy seems to be able to compensate for the difference in surface friction.
Dynamic & Static Friction = 1.0
Dynamic & Static Friction = 0.5
The final gait for the two control policies seems fairly similar. The lower friction environment may be using a longer stride but its hard to tell. I’ll try plotting this data when I figure out a good way to represent it. The lower friction surface is probably more representative of the real world. As of now the 3D printed materials do not provide a good grip on most surfaces. When I run this test on hardware I may need to use something like a rubber mat.
Reward Shaping : Ankle Angle Penalty
I added a small penalty for the difference in ankle angles to promote a more symmetrical gait, this may just be my own bias but I’m also curious how it will perform. Below is a plot of the rewards for the two cases. For this test I kept the lower contact friction so I’ll compare the results here to those earlier tests.

This is pretty interesting, Initially the policy rewards were fairly similar. At first I was worried that the plateau for the foot-fixed reward was indicating that it was not feasible for this particular design to find a stable gait but eventually it found success around 4M iterations and in the end achieved a similar reward to the policy that had the foot angles reversed. Upon looking more closely, the red plot seemed to have a similar situation but was able to discover ‘something’ that allowed it to achieve the peak rewards. Lets look at what is happening before this learning moment.
It appears that the bots don’t have a problem staying alive or walking, but they have a fear of reaching the goal.
When bots reached the goal, the sudden change of goal coordinate caused they to immediately fall down.
The policy looks like it tries to avoid reaching the goal while approaching to maximize the reward given.
The closer a bot gets to the goal the more points they stand to achieve.
Fixing Small Mistakes : Self Collision
While observing the previous example, I noticed that the robot was learning a policy where the legs were passing through each other slightly. I had messed up one of the parameters during the environment creation. After enabling self collision the policy was no longer working (expected). Instead of waiting 8+ hours to relearn the policy, we can cause use the a previous policy as a starting point. I was surprised how quickly it was able to recover from the change. I let it learn for another 6M ish steps but no further improvements were made.
Experiment Name : WalkBot_testing_077_Term0p13_footfix_part2
Starting Checkpoint : WalkBot_testing_077_Term0p13_footfix

It appears walking with the feet closer to the center line was helping it move faster. With collisions turned on it couldn’t achieve as high of a score.
Simulation Parameters : dt
I was trying to plot the joint angles during a period of walking, my hope was to see some periodic patterns in the legs phase space. I noticed that the data is a little sparse and often there are only two to three points per cycle. When the dt is decreased the walking policy starts to perform poorly. I think the lack of ability to generalize what to do might be tied to learning with a dt value that was too large.
One thing I was thinking about was what type of dt I can expect from my hardware.
Motor Data
Communication with the motors is maxed out at 4 Mbps.
DOF state per motor consists of a velocity and position measurement
Each of these measurements has 4 bytes
For 6 motors I would expect to receive 48 bytes of data
I also need to send a request message which is about 12 bytes so total data transfer for the DOF state is about 60 bytes or 480 bits
Given no down time, I could potentially achieve 10 kHz for the DOF state update.
IMU Data
I have one that can communicate and be powered from USB which is convenient
data rate specs is 500-ish Hz.
I have an invasense IMU that I used for a previous project where I got to 1.6 kHz
If I remember correctly it was specked higher (4 kHz) but the drivers weren’t cooperating
This is maybe a REV 2 solution, going to keep it simple for now
Going to use 480 Hz for the simulation. It feels like a good place to start
I suspect i’ll need to change the episode length and scale the rewards to get results that are comparable to the previous data.
480 Hz is an integer multiple (8) of the current 60 Hz rate. This will make scaling other things a little easier
episode length increased from 500 to 4000
all rewards scaled down by 1/8
To make this all easier, I added a new parameter to the yaml file called ‘dt_mod’. I don’t want to be chasing number chases all over my code so this will handle scaling all the things.
I don’t currently give any points for actually achieving the goal. If I did, I don’t think this type of reward would need scaling.
Like the previous test, we will start this learning experiment from a previously successful policy to speed up the learning time.
Experiment Name : WalkBot_testing_077_Term0p13_footfix_dt480
Starting Checkpoint : WalkBot_testing_077_Term0p13_footfix_part2